Mr David Baker Effendi, an MSc-student in Computer Sciences at Stellenbosch University, has received an Amazon Research Award based on his innovative research in program analysis with applications in bug-finding and cybersecurity.
The Amazon Research Awards include cash and Amazon Web Services (AWS) promotional credits for making use of Amazon's cloud computing resources. David says the award will help to cover his tuition fees and living expenses but, most importantly, it will provide him with much needed computing resources for his experiments and research.
In his research, under the supervision of Prof Brink van der Merwe, David combines graph theory and machine learning for automated vulnerability detection in software. His research thus far has led to collaboration with Dr Fabian Yamaguchi, chief researcher at the code security platform ShiftLeft, and the introduction of a computer security module on Honors level at Stellenbosch University.
He says many companies learn the hard way when neglecting to use thorough analysis and security tests on their software: “This is often a result of resource cuts in security checking as it takes up a large amount of the project timeline," he explains.
Recent examples of security breaches and cyber attacks include those at Liberty Life in 2018 and Virgin Active in 2021.
“The continuous vulnerability discovery engine I am developing with Dr Yamaguchi addresses this by saving results from previous analysis and efficiently updating the results to reflect new code changes. That is, if source code changes, only the intermediate representation of modified functions require recalculation."
Additionally, the engine enables efficient derivation of data dependencies for whole-program graph representations as employed by machine-learning-based program analysis. This means that further research into how machine learning models can be trained to consume program snippets, will help us understand how this can be used by the engine to translate newly-added code. These machine learning models can then help guide the engine to discover vulnerabilities and thereby reduce unnecessary analysis costs (see representation below).
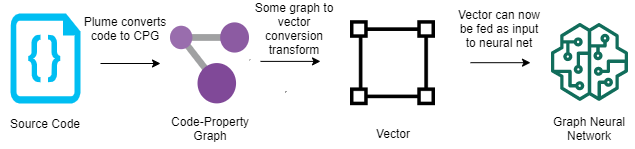
The engine was created keeping in mind the workflow of how code is developed and deployed in industry, meaning it can be integrated into code editors and development pipelines.
David says he enjoys seeing the immediate impact of his contributions: “I've been able to work with people from all over the world and see the results of my contributions in enabling others to make better software. I think this holds true in terms of contributing to and maintaining open-source projects in general."
“It is also really rewarding to know how to break something someone made and then help them fix it!" he adds.
For those interested in graph-based data science and how it is being applied in the field of cybersecurity, David provides a more technical explanation:
In the field of computer security, my research covers the sub-domain of program analysis and, more specifically, dataflow analysis. What this entails is tracking how information flows throughout a program and analysing how this can affect a system. For example, if an attacker sends tainted data as an input and this is not correctly handled, then it could adversely affect the normal functioning of the system and be exploited by the attacker to potentially result in data leaks, escalation of user privileges, etc. With dataflow analysis, we can follow the data paths and flag cases like these where input sources (e.g. web forms) are not correctly sanitized before reaching sensitive sinks (e.g. databases).
This type of analysis is often used by clients who wish to detect and fix bugs in their systems, or to give penetration testers and hackers a leg up in where to poke around in a given system.
Programs can be mapped to mathematical graphs as an intermediate representation where these paths can be analysed. These graphs consist of nodes and relations, where a node can represent a point or structure in a program and an edge can represent how the data flows or how some structure relates to another node. The representation we are using is called a "code-property graph" which, as the name describes, is a graph mapping code with properties of the code attached to these nodes and edges.
A big advantage of this representation is that any programming language can be projected into this format and the analysis does not need to be re-written for every language. My target program input is Java Virtual Machine (JVM) bytecode.
Using code-property graphs to represent program code has been very effective in dataflow analysis. Unfortunately, these graphs don't scale well and use more and more resources the larger the program. The idea of updating the existing results and graph with a code change to save time is nothing new but is scarcely implemented as it is often simpler to re-run the analysis. Uncompressed, a code-property graph can end up consuming multiple times the size of the original program in storage. Not only can storage be an issue, but to then load these results into an analysis can take a lot of time itself. This is often why security scans are neglected or unattractive as this slows down the development process. With my research, the practicality of incremental research is investigated and proven with real software and large programs tested against storing results in real graph database systems.
Graph database systems are databases that use the graph structure for how data are represented, stored, and queried. These systems have been very successful in product recommendation, contact tracing, network/operations mapping, and fraud detection. Using these as the storage layer for our incremental analysis we have seen significant improvements in analysis times as they are designed to efficiently store and answer graph queries against large graphs.
How are you using machine learning in this process?
The next contribution flirts with the idea of graph neural networks (GNNs). Program analysis has seen some success in training neural networks to identify bugs in programs based on training the models against these graph representations of code. The benefit of using neural networks to classify whether something has a bug or not is that it is fast. This is a slightly controversial topic in computer security as papers are arguing on both sides as to whether it works or why it doesn't. Yet the problem seems to be rather the fact that no good datasets are available and it being very costly to create one. Despite this, there are applications available that could further speed up the program analysis cycle and there has been successful attempts in using GNNs for program similarity, AI code completion, type inference, and detecting the presence of vulnerabilities in programs which are all areas that the rich code property graph representation could further enhance. Our first steps will most likely use GNNs as an aid to our existing techniques rather than a replacement altogether.
Tell us more about your collaboration with dr Fabian Yamaguchi, chief scientist at ShiftLeft?
All my work can be found as an open-source project at https://github.com/plume-oss. As part of my research, I developed Plume. Plume is used as the official JVM bytecode front-end to build code property graphs for Joern which is maintained by ShiftLeft where I am working closely with their chief scientist Fabian Yamaguchi. In 2020 Plume earned second place in a global hackathon organized by TigerGraph
Fabian Yamaguchi and I will be presenting a new cybersecurity module in the computer science honours stream. This module will be open to students from other faculties interested provided they get the relevant permission. The code is RW746 and the homepage can be found at https://cs.sun.ac.za/courses/computer-science-security/
